



1. SQLAlchemy & Flask-SQLAlchemy
SQLAlchemy는 Flask 혹은 어떠한 웹 개발 프레임워크로 사용하는 다양한 프로젝트에서 SQL과의 통신하기 위해 사용되는 Extenstion입니다. 이를 이용하면 ORM(Object Relational Mapping)을 보다 편리하고 간편하게 활용할 수 있습니다. 따라서 설계 소요 시간을 배분할 때 비즈니스 로직에 대해 집중할 수 있도록 도와줍니다. 이러한 SQLAlchemy는 프레임위크별로, 언어별로 사용하는 문법과 방법이 조금씩 다르지만, 전체적인 원리는 같습니다.
1.1 ORM(Object Relational Mapping)
ORM이란 객체와 관계형 데이터베이스의 데이터를 자동으로 매핑(연결)해주는 것을 말합니다. 가장 주요한 특징으로는 다음과 같습니다.
•
ORM을 통해 객체 간의 관계를 바탕으로 SQL을 자동으로 생성하여 불일치를 해결함
•
객체를 통해 간접적으로 데이터베이스의 데이터를 다룸
ORM에 대한 장점과 단점에 대해서는 나중에 자세히 다뤄보도록 하고, 설명은 간략히 여기서 마치도록 하겠다.
Flask-SQLAlchemy는 SQLAlchemy를 flask에 적용할 수 있도록 python으로 짜여진 Extenstion입니다. flask에서 sqlalchemy 모듈을 pip install을 통해 설치하여 사용할 수 있지만, flask를 활용할 때는 Flask-SQLAlchemy를 이용하는 것이 편리합니다. Flask SQLAlchemy에 대한 여러 블로그 글을 참조했을 때, 버전이 낮은(flask-sqlachemy 1.x) 예제가 많습니다. 이를 참고하여 학습 및 개발할 경우, 커뮤니케이션 오류가 발생하며, 소스코드를 비효율적으로 작성할 가능성이 있습니다. 따라서 Flask-SQLAlchemy Document를 참조하여 개발할 것을 추천드리며, 이 포스트에서는 Flask-SQLAlchemy 2.x를 기준으로 사용법과 효율성을 분석에 대한 내용을 서술하고자 합
1.2 flask-sqlalchemy v1.1 사용법 및 선언 방법
sqlalchemy와 flask-sqlalchemy를 선언하고, 이를 사용하기 위해서 과거에는 많은 코드를 추가 했었습니다. Database와 통신을 위한 session을 따로 만들어주고, db와의 연결 또한 수동적이었습니다.
아마 인터넷의 많은 블로그 글이나 과거의 글을 살펴보면 위와 같은 예시로 Tutorial이 작성된 글들을 볼 수 있을 것입니다.
데이터베이스 모델 선언 예제(v1.1)
from sqlalchemy import Column, Integer, String
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class User(Base):
id = Column(Integer, primary_key=True)
name = Column(String)
def to_dict(self):
return {"id": self.id,
"name": self.name}
Python
복사
데이터베이스 engine & session 선언(v1.1)
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
engine = create_engine("sqlite://") #your engine setting
session_factory = sessionmaker(bind=engine)
Python
복사
Flask application 인스턴스화 & 쿼리 사용 방법 예제(v1.1)
from flask import Flask, abort, jsonify
from flask_sqlalchemy_session import flask_scoped_session
app = Flask(__name__)
session = flask_scoped_session(session_factory, app)
@app.route("/users/<int:user_id>")
def user(user_id):
user = session.query(User).get(user_id)
if user is None:
abort(404)
return flask.jsonify(**user.to_dict())
Python
복사
1.3 flask-sqlalchemy 2.x 사용법 및 선언 방법
flask-sqlalchemy 2.x에서는 기존의 v1.1보다 간편하게 선언하고 이용할 수 있습니다. 아래와 같은 선언 방법을 이용하면 보다 쉽게 sqlalchemy를 선언할 수 있습니다. 또한 model에 선언된 db 클래스 변수를 import하여 필요한 영역에서 사용할 수 있도록 init_app() 함수를 지원합니다.
데이터베이스 모델 선언 예제(v2.x)
app.config 아래에 있는 SQLALCHEMY_DATABASE_URI는 configuration keys에 선언되어있는 기본 변수 이름입니다. 초기화를 간편하게 하기 위해서는 해당 변수에 engine 정보(SQL 접근 정보)를 꼭 입력해주어야 합니다.
#/app/models/__init__.py
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:////tmp/test.db'
db = SQLAlchemy(app)
class User(db.Model):
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(80), unique=True, nullable=False)
email = db.Column(db.String(120), unique=True, nullable=False)
def __repr__(self):
return '<User %r>' % self.username
Python
복사
데이터베이스 engine & session 선언(v2.x)
SQLAlchemy(app)을 선언한 클래스 변수인 db를 import하여 이용해야 합니다. models 아래에 선언된 db 변수를 이용하여 init_app() 함수를 실행합니다.
#/app/__init__.py
from app.models import db
def create_app():
app = Flask(__name__)
db.init_app(app)
return app
Python
복사
Flask 실행 예제
#/run.py
from app import current_app
app = create_app()
if __name__ == "__main__":
app.run(debug=True, threaded=True, host="0.0.0.0", port=4000)
Python
복사
db.session (example)
#/app/admin/users.py
from app.models import db, User
@admin.route("/admin/users", methods=['GET'])
def users():
users_data = db.session.query( User.username, User.email).all()
return render_template("/admin/users/index.html")
Python
복사
2. SQLAlchemy & MySQL Connection
기존의 설계와 같은 경우, Database 모듈을 따로 작성하고, 이를 필요한 함수에서 클래스를 선언하여 사용합니다. 모듈과 호출하는 예시는 다음과 같은 구조로 되어 있습니다.
2.1 PyMySQL을 이용한 Database 모듈 설계와 호출 구조 예시
아래에는 PyMySQL을 이용한 데이터베이스 모듈과 호출 구조를 설명한 내용입니다. 아래와 같이 설계된 패턴으로 개발을 할 경우, database class가 선언되고 함수가 종료되더라도, python과 mysql간의 connection에 대해 종료되지 않고 TIME_WAIT이 될 때까지 대기상태가 됩니다. 이는 하나의 프로세스 내에서 여러 개의 커넥션이 TIME_WAIT상태로 유지되는 현상을 야기할 수 있습니다.
데이터베이스 모듈
#/app/module/database.py
import pymysql
class Database():
# Connects to the specific database.
def __init__(self):
self.conn = pymysql.connect(host=app.config['DATABASE_HOST'],
user=app.config['DATABASE_USER'],
password=app.config['DATABASE_PASS'],
db=app.config['DATABASE_SCHEMA'],
charset='utf8')
self.curs = self.conn.cursor(pymysql.cursors.DictCursor)
if not hasattr(g, 'mysql_db'):
g.mysql_db = self.conn
def execute(self, query, arg={}):
self.curs.execute(query, arg)
def executeOne(self, query, arg={}):
self.curs.execute(query, arg)
row = self.curs.fetchone()
return row
def executeAll(self, query, arg={}):
self.curs.execute(query, arg)
rows = self.curs.fetchall()
return rows
def commit(self):
self.conn.commit()
Python
복사
데이터베이스 호출 예시
#/app/main/index.py
# -*- coding: utf-8 -*-
from flask import Blueprint, request, render_template, flash, \
g, session, redirect, url_for
from flask import current_app as app
from app.module import notice, database
main = Blueprint('main', __name__, url_prefix='/')
@main.route('/', methods=['GET'])
def index():
# ======================================================================
# 데이터베이스 세팅
db_class = database.Database()
# ======================================================================
# 데이터베이스 사용
query ="""SELECT *
FROM table_name
WHERE condition_01"""
result_data = db_class.executeAll(query)
# ======================================================================
# 템플릿으로 데이터 반환
return render_template('/main/index.html', result=result_data)
Python
복사
Too Many Connection with python3 process(TIME_WAIT)
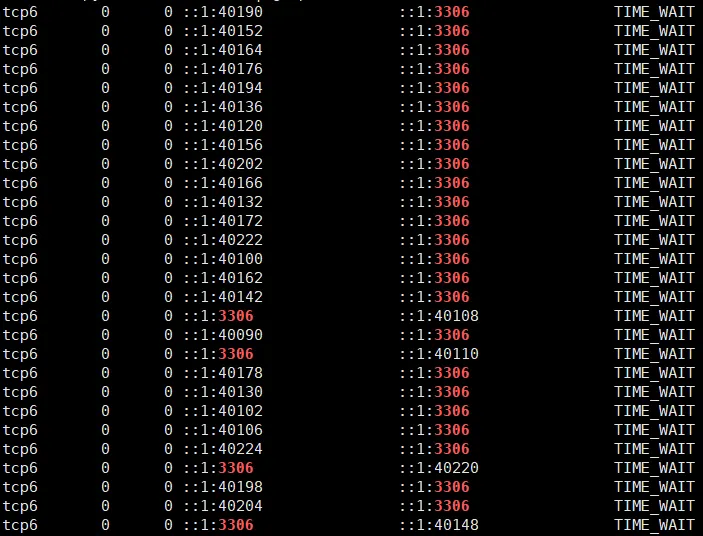
위와 같은 상태가 발생하게 됐을 때, 만약 100명의 이용자가 MySQL을 동시에 사용한다고 한다면, 100개의 커넥션이 동시에 발생하게 됩니다. 그리고 다시 한번 100명이 동시에 접속하게 되면 기본 max_connections 수(Default : 151 hosts)를 초과하게 되어 Too Many Connections Error가 발생할 수 있습니다. 따라서 서비스가 제대로 동작하지 않고 Internal Error가 발생할 가능성이 커집니다. 이를 위해 임시로 max_connections 수를 변경해주는 것도 하나의 방법이 될 수 있습니다. 그러나 이런 방법으로는 예상 가능한 자원을 계산하고 운영하기에 무리가 있을 수 있습니다.
2.2 Flask-SQLAlchemy 적용 예시
Flask-SQLAlchemy를 적용하여 설계한다면, Worker(Flask)와 프로세스(혹은 쓰레드) 간의 session이 계속 유지된 상태로 운영됩니다. 따라서 로직 상, 혹은 다른 에러가 발생하지 않는다면 SQL과의 연결이 끊기지 않고 안정적으로 운영이 가능합니다. 이는 다시 말해 프로세스당 SQL과의 Connection이 중복으로 이루어지지 않게 되고, Too Many Connections Error를 개선할 수 있음을 의미합니다.
app 작성 예시
#/app/__init__.py
# SQLAlchemy && Migrations
from sqlalchemy import create_engine
from app.utils.migrations import migrations, create_database
# Models
from app.models import db
# Flask
from flask import Flask
def create_app(config="app.config.Config"):
app = Flask(__name__)
# Set Config
app.config.from_object(config)
with app.app_context():
# Create Database(if it doesn't created)
url = create_database()
# Set MySQL's charset to utf8mb4 forcely
app.config["SQLALCHEMY_DATABASE_URI"] = str(url)
# Register Database
db.init_app(app)
# Create DB Session & Engine (if db is not defined, create table too.)
db.create_all()
from app.main import main
from app.admin import admin
app.register_blueprint(main)
app.register_blueprint(admin)
return app
Python
복사
SQLAlchemy를 이용한 Database Model 설계
#/app/models/__init__.py
from flask_sqlalchemy import SQLAlchemy
db = SQLAlchemy()
class Users(db.Model):
__tablename__ = "users"
__table_args__ = {'mysql_collate' : "utf8_general_ci"}
# Core Attributes
idx = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(128))
password = db.Column(db.String(256))
email = db.Column(db.String(128), unique=True)
# Your Database Models...
Python
복사
SQLAlchemy 선언 및 사용 예시
#/app/main/__init__.py
from flask import current_app as app
from flask import (
Blueprint,
request,
redirect,
url_for,
render_template,
)
from app.models import db
main = Blueprint("main", __name__)
from app.main import sign
@main.route("/", methods=['GET', 'POST'])
def index():
if request.method == "POST":
'''
Do Something
'''
return redirect(url_for(".index"))
else:
return render_template(f"/main/index.html")
Python
복사
#/app/main/sign.py
from flask import current_app as app
from flask import (
request,
redirect,
url_for,
render_template
)
from app.utils.security.auth import (
signin_user,
signout_user
)
from app.models import db, Users
from app.main import main
from hashlib import sha3_512
@main.route("/sign", methods=['GET'])
def sign():
return render_template(f"/main/sign.html")
@main.route("/sign/in", methods=['POST'])
def signin():
username = request.form.get("username", type=str)
password = sha3_512(request.form.get("password", type=str).encode()).hexdigest()
user_info = db.session.query( Users.idx,
Users.name,
Users.email,
Users.admin ).\
filter( Users.name == username,
Users.password == password).one_or_none()
if user_info == None:
return redirect(url_for(".sign", r="failed"))
else:
signin_user(user_info)
return redirect(url_for(".index", r="success"))
Python
복사
2.3 SQLAlchemy 세션 유지 & 보안 이슈
위와 같이 SQLAlchemy를 이용하여 Session이 지속적으로 유지되는 경우, 레이스 컨디션에 대한 Security Issue가 있는지 의문이 들 수 있습니다. 그러나 이러한 문제는 Python의 GIL 구조를 이해한다면 이러한 문제가 발생할 가능성이 적다는 것을 알 수 있을 것입니다.
Python GIL 요약
Python은 하나의 Thread만이 Byte Code를 실행할 수 있는 권한을 줍니다. 이는 다시 말해 다른 Thread가 실행되더라도, 다른 Thread들은 자원을 Acquire 하기 전에는 아예 실행조차 할 수 없다는 뜻입니다. 따라서 SQLAlchemy의 세션은 하나이고, 이 세션이 통신을 진행 중이라면, 통신이 완료되기 전까지는 다른 통신을 수행할 수 없다는 뜻입니다.
Max Connections Error 완화
Flask-SQLAlchemy를 사용하게 되면, 한 Worker당 DB와의 Connection이 이루어지고 유지되게 됩니다. 이렇게 하면 Flask와 DB간의 연결 문제에서 발생할 수 있는 다양한 문제에 대해 보다 자유로워질 수 있습니다. 이를 통해 효율적인 자원 관리가 가능하며, 정량적으로 자원을 측정하고 사용할 수 있습니다.
3. Conclusion
3.1 생산성 향상 및 코드 개선
Flask-SQLAlchemy을 이용하여 개발하게 되면, ORM의 장점을 그대로 가져와 생산성 향상의 효과를 가져올 수 있습니다. 코드로 선언된 Object(Model)에 대해서만 집중하면 되기 때문에 SQL Query가 아닌 직관적인 코드로 데이터를 조작할 수 있습니다. 이를 통해 쿼리 선언, 요청, 종료 등에 대한 작업에서 보다 자유로워 집니다.
3.2 효율적인 운영 및 자원 계산
Python GIL에 대한 이해를 토대로 간단히 정리해보도록 하겠습니다. 웹에서 동시에 100명이 통신을 수행하기 위해서는 WSGI(or Gunicorn, uWSGI, etc)에 선언된 processes * threads 수가 100보다 크거나 같아야 SQL과 유연하게 통신이 가능하다, 라고 할 수 있습니다. 이를 통해 동시 접속자 수에 따른 운영 방법을 효과적이고 효율적이게 관리하는 것이 가능해집니다.
•
Thread의 평균 세션 시간을 측정하여, 효율적인 Process/Thread 선언 수를 결정할 수 있음
•
운영을 위해 하나의 Core(물리 CPU)당 얼마나 Process/Thread를 선언해줄지 계산하고 운영 가능
•
불필요한 DB Connection이 발생하지 않아, DB 연결을 위해 발생하는 Overhead를 최소화할 수 있고, 불필요한 Process 생성이 되지 않음
•
불필요한 Connection Close가 발생하지 않아, 낭비되는 내부 자원을 감소 시킬 수 있음